Using GitHub as Artifactory for Machine Learning Model Artifacts
Sep 8, 2022Note: This blog post is part of my ongoing work on experiments with model training, deployment and monitoring repository bitbeast. If you liked this blog post, please upvote on Hacker News.
Source Code: GitHub
Background of Model Deployment at Skim
Last year, I launched Skim with my friends. It is a platform to find, manage and read research papers. The platform is powered by machine learning models for use cases like finding related papers and classifying research areas/tasks of the paper. At Skim, we use GitHub for most of our development, testing, integrations and releases. We also use GitHub Actions for carrying out small jobs using workflows. A point to remember, Skim is in BETA and built end-to-end totally for free. Thanks to services like GitHub, Fly and MongoDB.
When it comes to model deployment and running inference, we experimented with several options. From the beginning we were looking for a free alternative for our small-scale experiments. For example, post-training of the NLP models, we tried saving the weights and embeddings on cloud e.g. Dropbox, Google Drive and other similar services. This turned out very complicated due to their apps & tokens and their storage limits. From an integration perspective, this was not easy to maintain for developers. As mentioned earlier from a pricing perspective, something like Amazon S3 wasn’t enough for us to sustain. This paved the way to think of a solution can be closer to our version control system, easier when it comes to integration and also free!
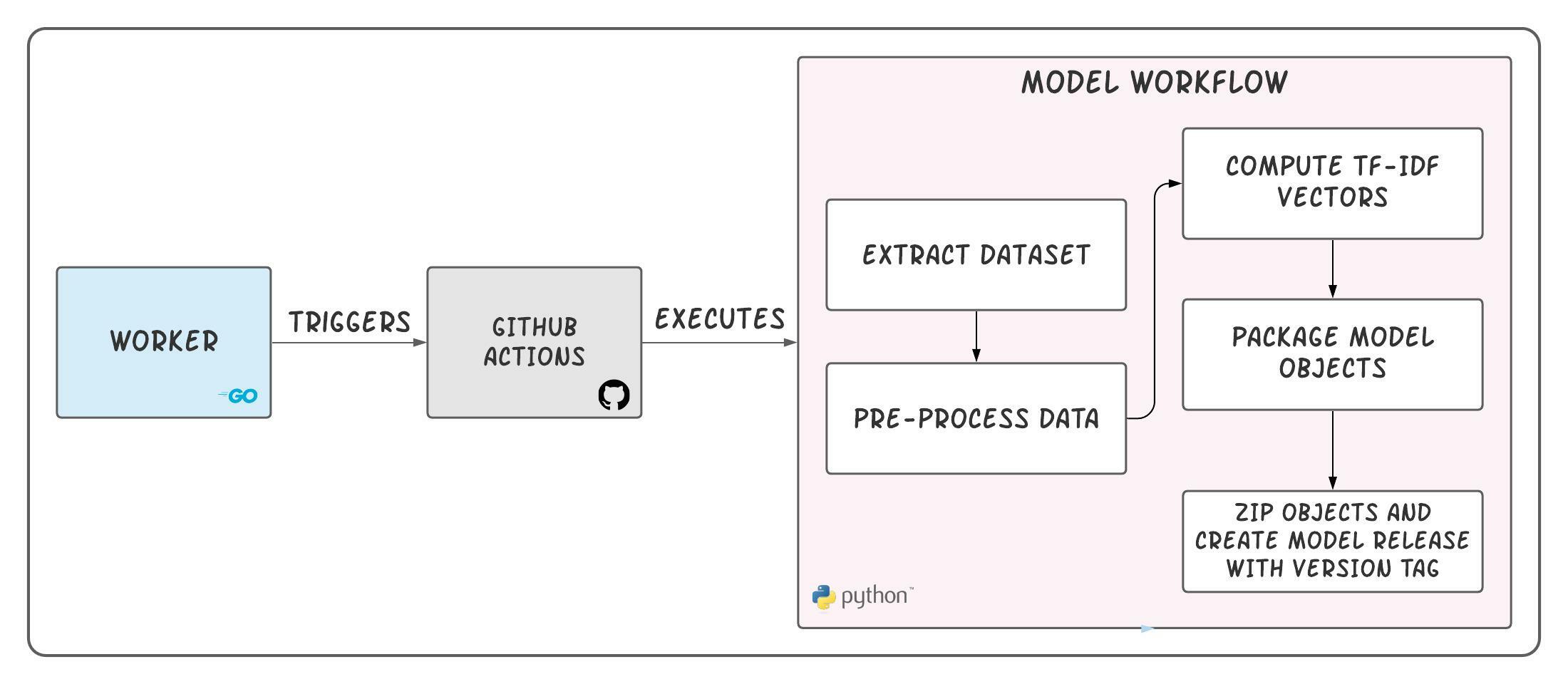 Skim ML Workflow
Skim ML Workflow
Challenges of Machine Learning Projects
From the context above, it is clear that every small-scale startup, open source project or self-hosted ML solutions go through following set of challenges:
- Keeping up with the pricing of Cloud Providers like AWS, GCP, Azure.
- Managing the integrations of these Providers in the research-to-production lifecycle.
- Improving the developer experience & learning curve of the researchers who turned into software engineers.

We need a simple solution for tackling these challenges that will requires less time and hustle to setup and integrate.
Introducing GaAMA & Use Cases
GitHub Releases are one of the best features because it allows you to release a version of your codebase along with some release assets. Now these assets doesn’t need to be part of your codebase, but it can be output of it. For example, a project can build & release distributions for each operating system. Similarly, we can use GitHub to release a version with our model weights, other artifacts, etc. Inspired by this simple idea, GaAMA was born. It does exactly as it stands for - GitHub as Artifactory for Model Artifacts. One can create a release of their repository on GitHub and upload their final outputs of training to those releases. Keep in mind, GitHub acts as a kind of simple model registry for you.
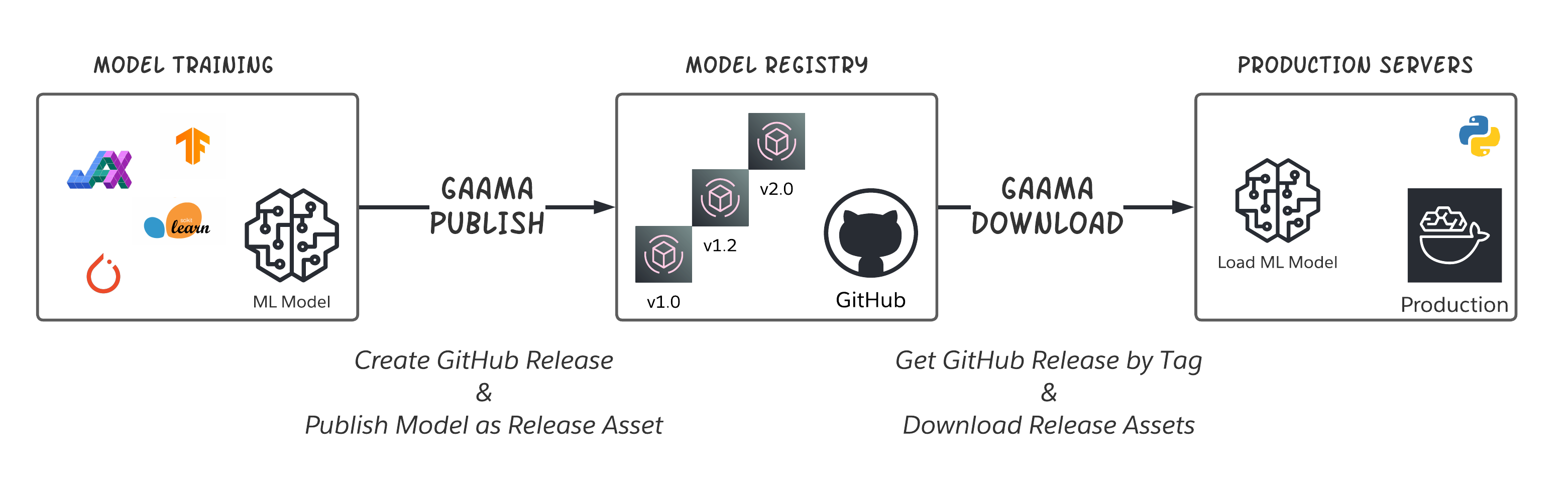 GaAMA Workflow
GaAMA Workflow
Use Cases
For both use cases as mentioned below, one has to install and initialize GaAMA.
Install GaAMA using:
pip install gaama
Initialize GaAMA with github credentials:
from gaama import GaAMA
gaama = GaAMA(username='<username>', password='<password or token>', owner='<github_repo_owner>', repository='<github_repo_name>')
A developer or a team who trains a model on Google Colab (or similar service) wants to release a version
gaama.publish(tag='<release version>', files=['model.pt', 'embeddings.npy'])
With just one line of code, you will be able to release & publish model of your choice!
A software engineer who is building a user-centric service, wants to load the model and run inference
gaama.download(tag='<release version>')
With just one line of code, you will be able to download the model of your choice on your production server!
You can also refer to this example notebook demonstrating the publish and download model artifacts with a PyTorch model.
Possible Improvements / Roadmap
- Model Versioning: Currently, does not have the capability for releasing models with Semantic Versioning. Yet, it does come with a calendar versioning (
YYYY.MM.DD) by default to make it easy for some users. - Artifact Compression: There is no in built compression that allows users to reduce the size of the artifacts. But, there is a simple zip functionality as of now. Also, a checksum looks useful in future for validating its contents.
- Language Support: At present, I made gaama for deployment in a Python runtime. This allows the ease of downloading and loading the model for inference. For users wanting to deploy in C++/Java environment, will have to wait or create a similar solution.
If you liked the idea of GaAMA, go check it out on GitHub. If you have an idea or a suggestion for improvement, feel free to contribute via Issues/Pull Requests!